News
Doing a systematic review/meta analysis on fuzzy phenomena
Maranke Wieringa (d.d. 4 June 2019)
Meta analyses or systematic literature reviews are taken to be the golden standard for assessing the collective knowledge on a particular topic. While frequently employed within the social and natural sciences, they are hard to put into practice in the Humanities, which do not often have strictly controlled experiments with comparable methods. Nevertheless, a comprehensive review of the discourse surrounding a particular phenomenon is valuable for Humanities scholars as well. In the present blog post, I will describe my own approach to doing a meta analysis on a ‘fuzzy’ phenomenon: that of ‘algorithmic accountability. I will first explain why a systematic review or meta analysis can be done on a ‘fuzzy phenomenon’ (i.e. when a term is not thoroughly defined). Secondly, I will explain how one can approach a systematic literature review/meta analysis using computational mapping of author-defined keywords in order to build the query. Thirdly, I will discuss how one can make sense of such a variety of articles by reading the literature diffractively through a guiding framework. Finally, I will discuss the value, and reliability and validity of such an approach.
Why would a systematic literature review/meta analysis work at all on a fuzzy phenomenon?
As research on algorithms and their impact is proliferating, so is the call for scrutinizing those algorithmic systems. As of yet, however, a systematic review of the work that has been done in the field is lacking. In my dissertation, I include a systematic review, following the ‘Preferred Reporting Items for Systematic Reviews and Meta-Analyses’, or the PRISMA statement (Liberati et al., 2009). While the PRISMA method was originally developed for the context of medical sciences, and thus not all its items will be applicable in a Humanities context, the core of its idea remain valid: a systematic, reproducible step-by-step evaluation of a body of work.
Using the PRISMA statement, I investigate what we need to account for when discussing algorithmic accountability. The concept of algorithmic accountability as of yet lacks a common, specific definition. Nevertheless, the problems coupled with algorithmic accountability, or rather, the lack thereof, are abundant. As the term ‘algorithmic accountability’ has only been adopted in the last couple of years, a focus solely on this term tends to obscure other, relevant material. Such texts may relate strongly to the topic, yet fail to mention this term explicitly for any number of reasons. Thus, in order to select articles relevant for this inquiry, a recursive query design strategy is adopted. This strategy allows for a bottom-up approach, by extracting the most relevant keywords from the literature itself and using those to construct a query. The recursivity lies in the iterative character of the search strategy, thus allowing for pluriformity in query design and the identification of relevant topics.
This immediately complicates the premise of a systematic review. Normally, such a review deals with a very clearly defined, and very narrowly focused topic (Denscombe, 2017, p. 150). Moreover, a systematic review generally focuses on a substantial body of studies sharing similar methods. It is normally used to review quantitative data, which ‘must lend itself to measurement, comparison and evaluation’ (ibid.). The astute observer may note that my situation does not seem to apply to these criteria. In fact, the entire foundation of this chapter may seem to go against these basic characteristics. Before proceeding to the actual review, I will take some room to argue why a systematic review under these conditions is not only possible, but also extremely valuable. This argument will be structured following the five criteria of systematic review as articulated by Martyn Denscombe (2017, p. 150):
1) The topic or problem being reviewed must be clearly defined and quite narrowly focused;
2) A substantial body of research findings must already exist on the topic;
3) The available evidence must come from studies that use similar methods;
4) The ‘evidence’ must lend itself to measurement, comparison, and evaluation;
5) The findings are usually based on quantitative data.
First, there are multiple ways in which one may define a topic or problem. One way is to simply use a common term for the phenomenon. However, there may not be a definitive term connected to the phenomenon, either because it is relatively new or because we use different terms to denote the same thing. To illustrate: if one were to search for material about World War I and one would fail to include ‘The Great War’ as part of their query, they would miss out on material from the historical moment of WW I. Names of phenomena or topics change, even though the phenomena they refer to remain the same.
What this particular review is interested is, is the phenomenon or topic of algorithmic accountability, not the term. As such, a different strategy was adopted in order to extract terms which are related to that topic. In other words, this systematic review takes as its starting point not a clearly defined term, but a clearly defined topic. As such, this first criterium can be said to be met after all.
Secondly, a substantial body of work is a requirement for the systematic review. In connection with the former point, I argue that ‘algorithmic accountability’ as a term is young and while productive does not produce a very rich body of work in itself. If we are to approach algorithmic accountability as a topic, however, we see that there is an incredibly substantial body of work which spans several disciplines. In other words, by addressing the phenomenon/topic instead of the term, one allows for incredible pluriformity and interdisciplinary takes on a subject. Thus, by casting the net wider – as we stop focusing on the exact phrasing, and more on the underlying meaning – we simultaneously allow for the substantial body of research to emerge.
Thirdly, it has been argued that the studies to be reviewed must share similar methods. While this undoubtedly facilitates easier comparison, I would like to argue that it is not a necessity. In topics where little systematic reviews have been done, showing the diversity of approaches could be beneficial. Moreover, juxtaposing studies from different disciplines and methodological underpinnings may help to triangulate what we know and what we do not know about a topic as a whole. In other words, precisely because these studies approach the subject from a heterogeneity of backgrounds using a plethora of methods, we can start to distill red threads which emerge throughout this body of research. Thus, we can use the diversity of research as a test to assess certain characteristics of the phenomenon. As such, the validity of one’s findings is not compromised. Moreover, such an approach takes generalizability as its key interest: surveying the existing literature in search of common ground, or the lack thereof.
A fourth criterium is that the research findings is measurable, comparable, and can be evaluated. As the triangulation argument above already demonstrated, things need not be of the same order so as to evaluate them. In fact, triangulation would argue that we need heterogeneity in order to verify our findings.
Another concern is perhaps a bit more fundamental: can everything that counts be counted? Here we touch upon some fundamental differences between the sciences and the humanities, but – without trying to enter into a debate about the ‘two cultures’ – it is worthwhile to consider the humanities equivalent of quantitative comparison. Just like quantitative results only gain their value when seen next to their counterparts, a qualitative comparison of texts, theories, and findings needs to be approached similarly. For this, I propose diffractive reading as an adequate strategy.
Diffractive reading entails ‘engaging with texts and intellectual traditions means that they are dialogically read “through one another” to engender creative, and unexpected outcomes (Barad 2007, p. 30). And that all while acknowledging and respecting the contextual and theoretical differences between the readings in question’. Thus, instead of interpreting the quantitative findings of studies, diffractive reading adopts a qualitative interpretation of texts. Instead of juxtaposing the quantitative results, we juxtapose thoughts, theories and, yes, quantitative results.
Thus, diffractive reading as a methodological stance is especially suited for interdisciplinary work, as it allows for ‘respectful engagements with different disciplinary practices’ (Barad 2007, p. 93). In a way, we can perhaps best describe this as a ‘yes, and’ rather than a ‘no, because’ kind of stance. Reading affirmatively through texts allows for new perspectives on what unites rather than what divides. Such a methodological stance, is then especially useful for a systematic literature review which, after all, aims to distill that which is known about a certain topic. Throughout this chapter I will adopt such a diffractive attitude, in order to extract the generalizable observations and the lacuna’s from the body of research. Using this diffractive engagement, I will read through key texts from governance studies on accountability so as to make visible what is or is not new about algorithmic accountability, and what areas of algorithmic accountability are currently underdeveloped.
Finally, there is the adagium that, generally, systematic reviews busy themselves with quantitative data. It is important to note that quantitative data is thus not a necessity, but an expected norm. In light of the above, I feel confident in deviating from this norm.
One my rightfully wonder why I would want to adapt a systematic literature review approach to fit an interdisciplinary research project. There are a number of reasons, but the foremost being that if one writes about accountability in any way, I believe it to be important that one also accounts for their own practice, perspective, and methodologies. Adapting the PRISMA statement for an interdisciplinary project like my own, allows for such an account. It allows for replicability in so far is replicability is possible at all, and it makes transparent much of what would otherwise remain obscured in the process of selection/exclusion. Thus, while not perfect, I believe it to be a logical step in moving towards the definition of the algorithmic accountability. Or, if you prefer going ‘meta’: I am trying to algorithmically account for my literature review on algorithmic accountability.
How to systematically review fuzzy phenomena
In order to accommodate the diversity of studies relating to the topic of algorithmic accountability, relevant associated terms need to be identified. This is done using a recursive query design (see fig. 1.). The recursivity lies in the repetition of steps and their subsequent snowball effect. First, an exploratory query is designed, based on the relational strength of the keywords of 27 pre-identified articles. Using this exploratory query we then collect new articles, and from those relevant we again extract keywords and assess their strength. This will create the basis for the final query.
Some justification is needed with regard to the procedure. Author-identified keywords added to academic articles were chosen as an indicator of relatedness. Keywords were chosen as indicator as they are created to briefly represent the content of an article and to be specific and legible to one’s field of study. In mapping the relations between keywords, oft-discussed themes should come to the fore, as well as the diversity of perspectives and terms between disciplines.
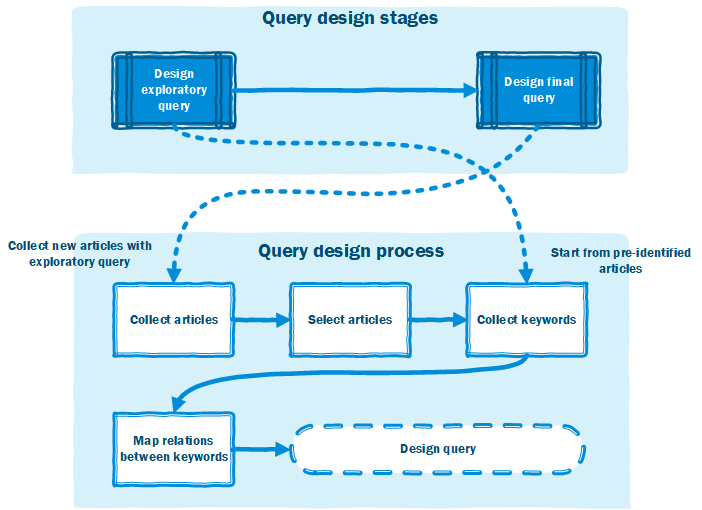
Fig. 1. Recursive query design stages (top) and process (bottom).
After the keywords were inventoried, they were made more generalizable, by using the * operator. After this, colocation of keywords were identified and mapped using network visualisation tool Gephi. The keywords which related the strongest to one another informed the new query.
Explanation |
The * operator and colocation mapping The star operator is used to search for all possible variations and/or different endings to words. For instance [govern*] would return ‘govern’, ‘governance’, ‘government’, and ‘governing’. Where one places the star is thus important. In the query design process, the stars were initially placed slightly different (i.e. [accountabl*] instead of [accountab*]). In the final query, stars were placed for maximum flexibility, so that for instance [accountab*] would return not just ‘accountable’ but also ‘accountability’. In charting the keywords’ collocations, first the individual keywords were related to the other keywords of the article. For instance, if the keywords of an article are ‘big data’, ‘algorithms’, and ‘accountability’, then the relations would be mapped as follows: big data algorithm* big data accountab* algorithm* big data algorithm* accountab* accountab* big data accountab* algorithm* |
Using the resulting definitive query, the corpus was selected. This material was selected by screening titles and abstracts for their relevance to the topic, and their adherence to the eligibility criteria.
Explanation |
The eligibility criteria
Aside from the query, there are some other factors to consider in a search strategy, for example the years you wish to cover, and publication type and the language of the works. As computational systems tend to become obsolete quite quickly, this study will cover the last ten years (2008 up to and including 2018). With an eye on future replicability of the study, the review will limit itself to those publications published in English. Only works that have been published will be reviewed (e.g. working papers will not be included). Only articles that present original academic work will be included (e.g. research article, review article), whereas, for instance, introductions were excluded.
|
So how did all of this work exactly? To start with 27 academic articles (Ananny, 2016; Ananny & Crawford, 2018; Bennett Moses & Chan, 2018; Binns, 2017; Binns et al., 2018; Bozdag, 2013; Burrell, 2015; de Laat, 2017; Diakopoulos, 2015b; Drew, 2016; Edwards & Veale, 2017a; Fink, 2018; Kemper & Kolkman, 2018; Kraemer et al., 2011; Lepri, Oliver, Letouzé, Pentland, & Vinck, 2017; Lustig et al., 2016; Mittelstadt et al., 2016; Neyland, 2016; Neyland & Möllers, 2017; Rahwan, 2018; Saurwein et al., 2015; Vedder & Naudts, 2017; Williamson, 2015; Yeung, 2017a, 2017b; Zarsky, 2016; Ziewitz, 2016) which were found to be relevant to the topic prior to the start of the systematic review were assessed for their keywords. These articles were all strongly connected to the topic of algorithmic accountability, explainability/transparency, ethics, decision-making, and governance. In other words, these articles were found to touch upon relevant aspects of my research project. Books, reports and academic articles without keywords were excluded from this exploratory inventory. As some keywords overlapped partially (e.g. algorithmic decision-making/algorithmic decision making/automated decisions/automated decisions) keywords were grouped together when overlap occurred (e.g. ‘decisions’). In total, 79 keywords were found after resolving this overlap. Next, for each keyword, of the article relation between the other keywords of the article was mapped. This lead to an inventory of 879 relations, or ‘edges’.
These edges were subsequently fed into the network visualization program Gephi (Bastian, Heymann, & Jacomy, 2009). Among the 879 edges, 752 unique ones were found, meaning there are 127 instances in which different articles use the same keywords. The collocations were visualized using the ForceAtlas2 algorithm (Jacomy, Venturini, Heymann, & Bastian, 2014).[1] From this exploration, those collocated keywords were selected which had the highest degree (both in- and out-degree). The threshold was set at degree >= 35, meaning that in order to be considered for the next step in building the query design, these collocated keywords had to have a sum of incoming/outgoing connections equal to or greater than 35 (fig. 2.). This left 9 nodes (11.39%), and 57 edges (7.58%).
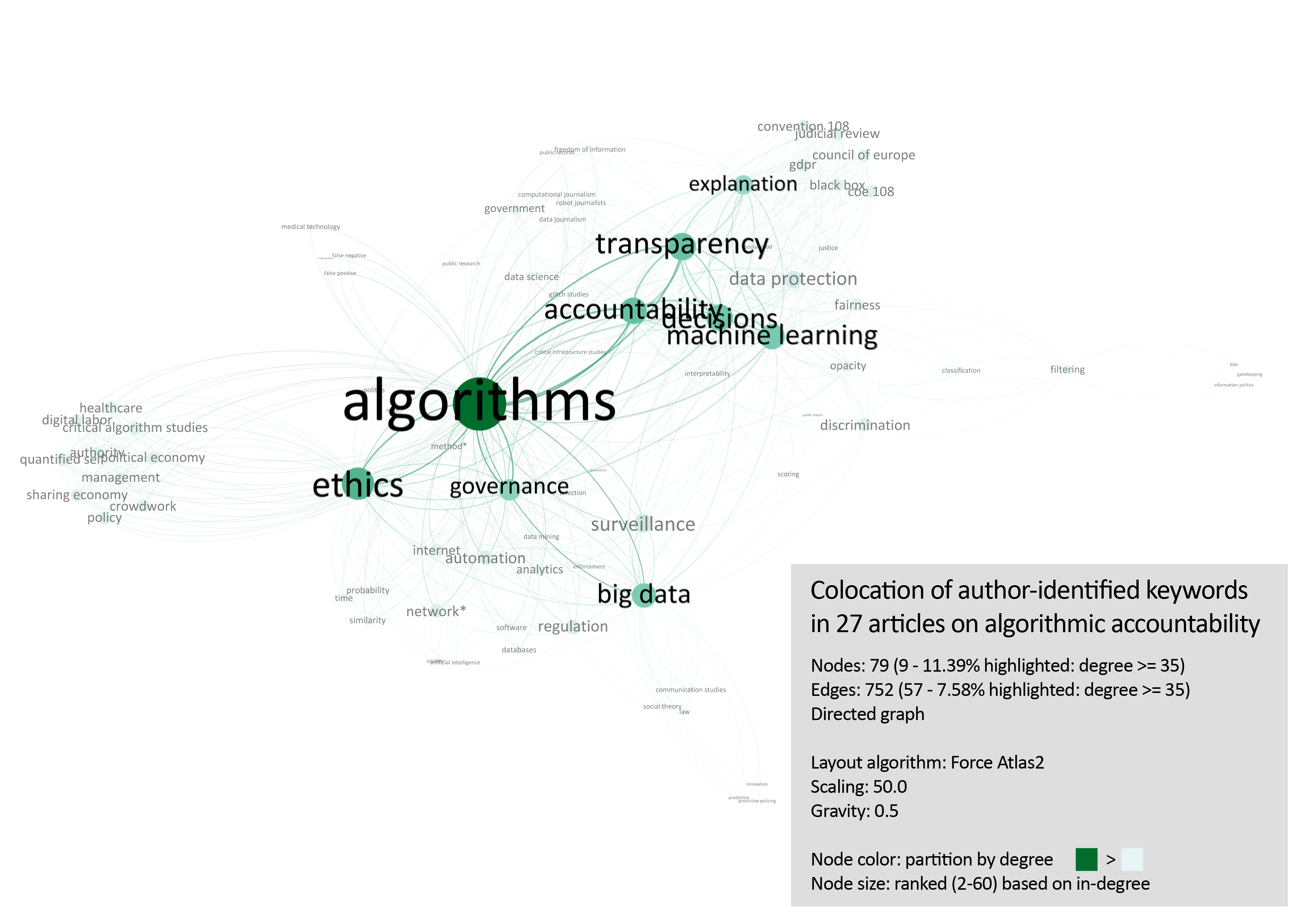
Fig. 2. Exploratory mapping of collocations of keywords in articles on algorithmic accountability, filtered on degree >= 35
This selection was subsequently used to build the query. The edges table of the filtered subset was exported, and duplicate relations were added together.[2] The result was ordered on edge weight (i.e. how strong/frequent the collocation is). These insights, together with the mapping of the collocations, allow for a first, considered query design. Whereas the combined edge weight conveys the strength/frequency of the relation between the terms. The network graph gives an indication of the discourses which draw on particular keywords.
After generating insight in the strength of the relations between the keywords, the strongest collocated keywords were selected for the query design. To this end, edge weights <= 4 were not included, however, where narrowing down the results was preferable as some terms could be quite general (e.g. ‘big data’) they were used to supplement the query.[3] The query that was designed based on the selection is as follows: [“algorithmic accountability” OR algorithm* AND accountabl* OR algorithm* AND accountabl* AND transparency OR governance AND algorithm* OR algorithm* AND transparency OR ethic* AND algorithm* OR transparency AND decision* AND algorithm* OR algorithm* AND “big data” AND governance OR algorithm* AND “big data” AND decision* OR transparency AND “machine learning” AND algorithm* OR transparency AND explanation AND algorithm* OR accountabl* AND decision* AND algorithm*].
This initial query was used to gather more relevant publications, and to subsequently finetune the query design. The exploratory query was used to search for more relevant articles, and those articles were then again used for a collocation mapping strategy in order to improve the query design. In other words, the query design is circular, so that potential bias emanating from the first batch of 27 articles which were seen as relevant, could be nullified – and initial assumptions about important keywords could be tested.
As articles were best suited to this approach – as they often include author-specified keywords – both Web of Science and SCOPUS were queried. Querying titles, keywords and abstracts in SCOPUS delivered 7.019 results in total. The search was then further specified for the period 2008-2018 (5.397 results), to include only English papers (5.145 results). Web of Science allows for searching a ‘topic’, which – similar to SCOPUS – encompasses the title, keywords, and abstract of a given work. Querying topics in the Web of Science resulted in 2.127 results for the period 2008-2018, of which 2.076 were English. As these results needed to be screened manually, the smaller corpus of Web Of Science was used for this second exploration, and the search results were exported as TSV files.
After their export, the files were cleaned. All data entries were screened using the same procedure. First, the title was checked for its relevance. An article is considered relevant if algorithmic accountability is the main topic of the publication.[4] If the title was found to be relevant, the article was included, if not, it was excluded. In case of doubt, the abstract is assessed for its relevance, following the same procedure. If doubt still remains after reading through the abstract, the publication is included provisionary (see fig. x for an overview of the entire process).
This screening resulted in 114 inclusions (5.5%), 99 provisional inclusions (4.8%), and 1.863 exclusions (89.7%). Thus, 10.3% of the results were found to be of (potential) interest. The 114 inclusions provided the basis for a second round of collocation mapping. Of the 114 papers, 25 (22%) articles were found to have no keywords, leaving 89 (78%) articles which did include such keywords. in which 270 keywords and 2870 collocations were identified. Again, these relations were investigated using Gephi.
Discussion |
The bias in keywords
Even though the query design attempted to be as inclusive as possible, the structure of the texts from particular disciplines meant that in this second phase some disciplines are underrepresented in the design of the query. Articles from a legal context were found to include keywords less often, for instance. While this means that these disciplines have less chance to feed into the new query, the designed query will nevertheless produce results from those fields, as not just the keywords themselves are queried, but also title and abstract. The disadvantage to that field is thus considered acceptable.
|
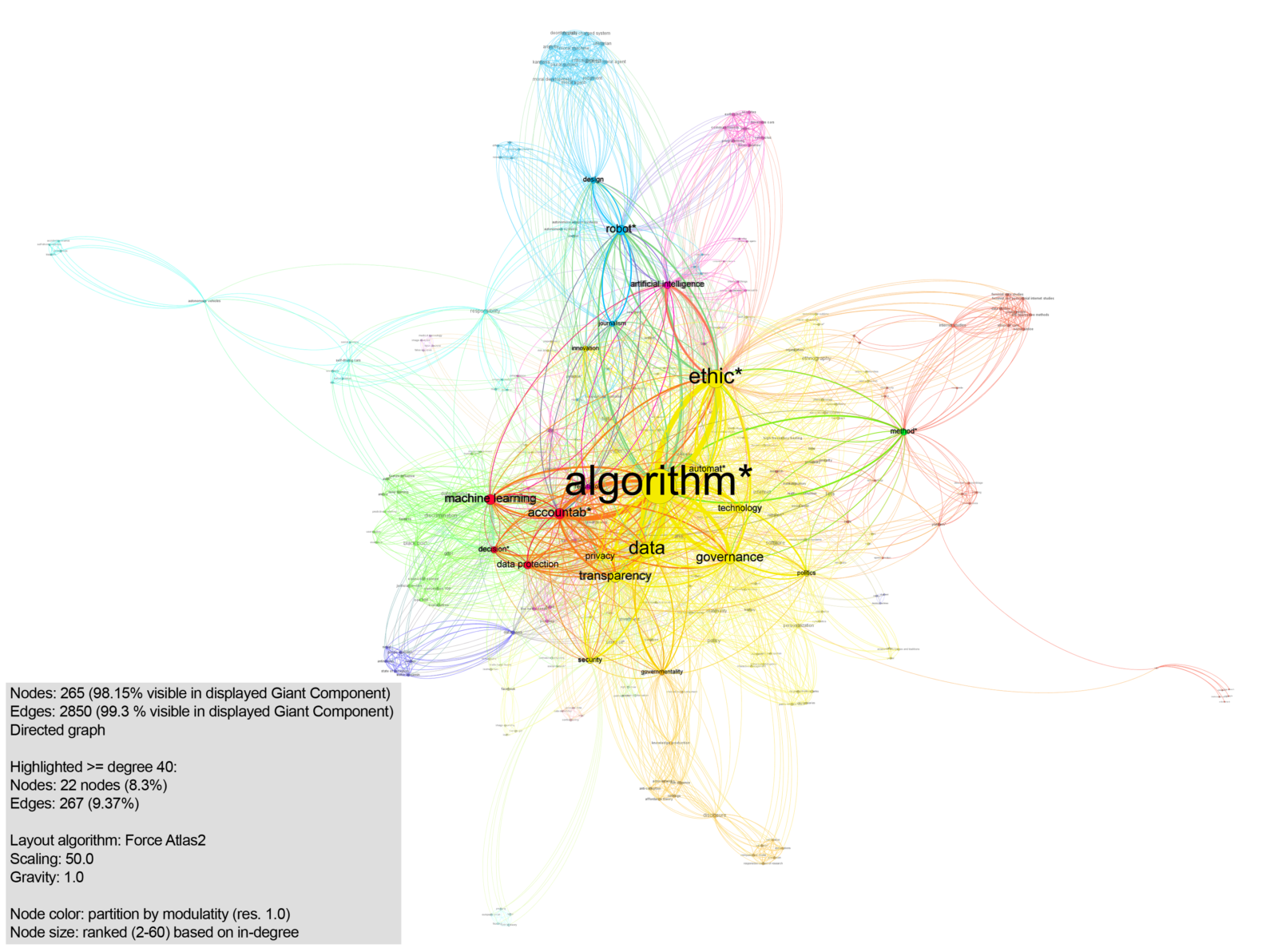
The network appeared to be connected, except for one paper (Gieseking, 2018), whose keywords did not overlap with any of the other articles. This single paper was excluded from consideration for the subsequent query design process. It was filtered out by using a Giant Component filter (98.15% of nodes and 99.3% of edges visible). The remainder of the connections were mapped using ForceAtlas2 (Jacomy et al., 2014). Modularity (Blondel, Guillaume, Lambiotte, & Lefebvre, 2008) was exploratively used with different resolutions (displayed in fig. 3: resolution 1.0) to see if keyword preferences amongst the various disciplines could be detected, but did not produce such results.
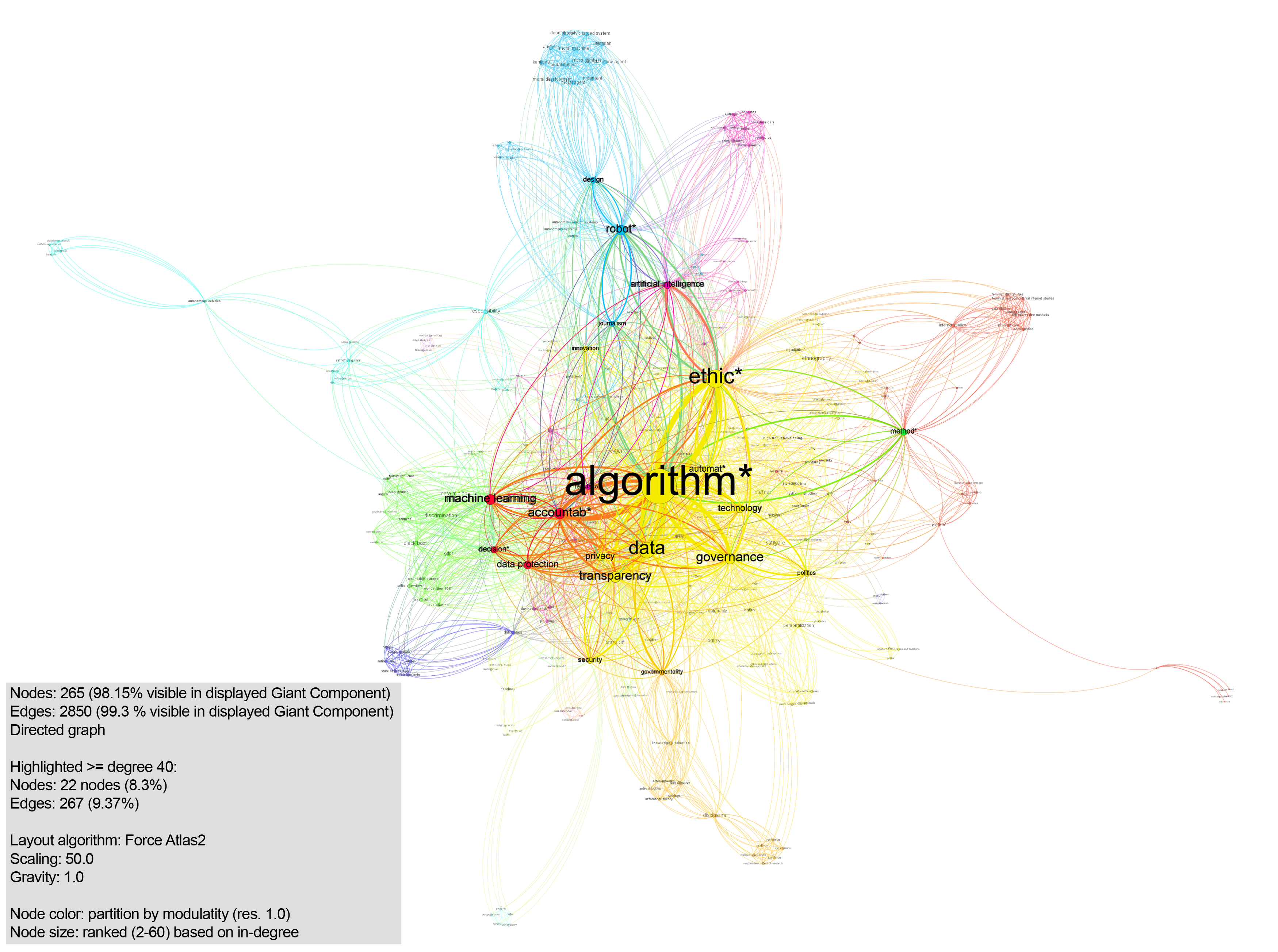
Fig. 3. Exploratory mapping of collocations of keywords in articles on algorithmic accountability, filtered on degree >= 40
Subsequently, the edges table was exported and the weights were combined as described earlier. As this second round of enveloped a greater number of relations – the cutoff point was not set at 4, but rather at 10. Thus, relations with a combined edge weight >= 11 were included in the final query design.
Discussion |
The bias in keywords II
In order to universalize keywords, combined keywords were split up into different words (e.g. ‘algorithmic accountability’ became ‘algorithm*’ and ‘accountab*’. However, in some cases, splitting the keywords would not do justice to the complexity of the keyword (e.g. breaking up ‘ethics of care’ in ‘ethic*’ and ‘care’, would not do justice to the concept). In such cases the original term was used, and where possible an extra keyword would be added (‘ethics of care’ and ‘ethic*’). In such cases, the break up would not be an OR, but a partial AND. This might skew the results, as ultimately the decision to either break up the keyword or not has been a human one, based on interpretation. Thus, a different researcher might break these keywords up in a slightly different fashion.
|
Using the combined edge weight, a new query was designed. As before, excluded terms might be used to complement very general terms where necessary. The final constructed query is as follows: [“algorithmic accountability” OR algorithm* AND ethic* OR algorithm* AND data AND ethic* OR algorithm* AND data AND transparency OR algorithm* AND data AND accountab* OR algorithm* AND governance OR algorithm* and accountab* OR algorithm* AND transparency OR algorithm* AND technology AND transparency OR algorithm* AND technology AND ethic* OR algorithm* AND technology AND accountab* OR algorithm* AND privacy AND transparency OR transparency AND accountab* AND algorithm* OR ethic* AND “artificial intelligence” OR algorithm* AND automat* AND decision* OR algorithm* AND “machine learning” AND transparency OR algorithm* AND machine learning” AND ethic*].
Using the specified query, SCOPUS, and Web of Science were searched on November 8th 2018. Similarly to the procedure in the query design stage, the databases were queried for the period 2008-2018, and only publications in English were included. Querying Web of Science generated 5.731 results for the period 2008-2018, of which 5.618 were in English. Due to SCOPUS’ limitation on the downloading of the complete information (a maximum of 2.000 entries at a time), the database had to be queried for each additional query separately and sometimes even had to be split per year. The separate files were taken together afterwards. Querying SCOPUS resulted in 19.892 hits for the period 2008-2018, of which 19.033 were in English. As the query was broken down, 2.845 duplicates had to removed, leaving 16.188 unique titles.
The 5.618 titles from Web of Science and the 16.188 titles from SCOPUS were subsequently manually assessed for their relevance (see fig. 4) following a similar procedure as per the query design stage (i.e. assessing relevance of the title/title and abstract). After this initial round, the (provisionally) included titles were taken together. This resulted 264 (provisional) inclusions from SCOPUS, and 204 (provisional) inclusions from Web of Science. After merging both corpora, this resulted in 371 titles. Subsequently final decisions were made with regards to the provisionally included articles (34 excluded), and corpus was limited to journal and proceeding articles (e.g. no book reviews, introductions to special issues). This resulted in a final selection of 242 articles. The articles’ sources were checked against Beall’s list (2018) of predatory journals, but no predatory outlets were found among the selection. In order to prioritize and group the reading material a rudimentary affinity mapping (Plain, 2007) was done based on the titles and abstracts. As I am still in the process of analysing the material itself, and in those analyses sometimes have to exclude material (e.g. not a research article), the final number of articles that will be included in the meta analysis is currently unknown.
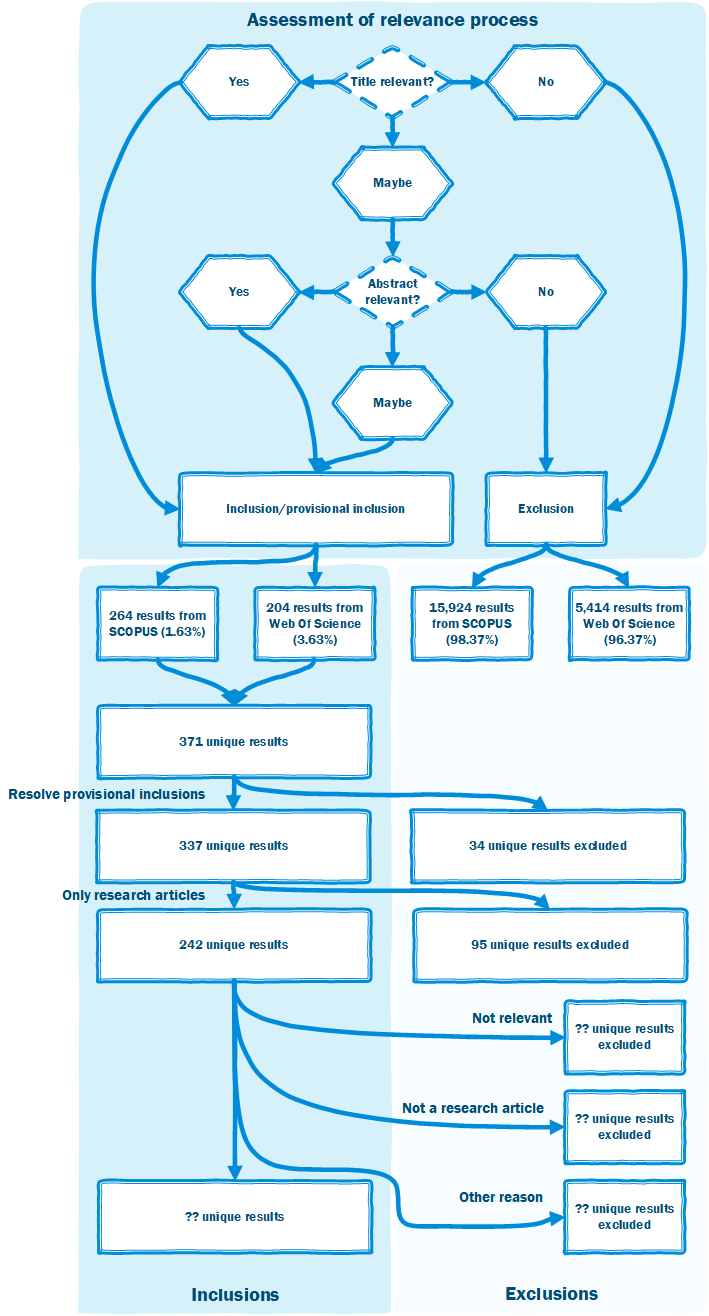
Fig. 4. Flowchart of selection process
Making sense of the articles
As assessing 242 very different and interdisciplinary articles is a daunting task, one needs more structure. I found that structure by reading the selected articles diffractively (Barad, 2007, p. 30; Geerts & Van der Tuin, 2016), which allows for an interpretation through a governance studies accountability framework. Such an assessment is valuable, as, even though the term would suggest otherwise, algorithmic accountability’s connection to accountability theories is underdeveloped. Borrowing these accountability frameworks from governance studies (e.g. Bovens, 2007), provides us with a clear interpretative lens and framework to assess the current body of work in light of existing accountability theory, and lets us answer the question: what do we need to account for when accounting for algorithms?
Discussion
The approach sketched above has some pros and cons that deserve some attention. Let us start with the pros: I found it incredibly helpful to get such an interdisciplinary overview of my field. Even in manually screening the titles and abstract, one for instance gets an impression of the themes being discussed by which fields (e.g. moral machines/trolley problem). For me, it is also a way to systematically engage with the topic of algorithmic accountability and to firmly embed and situate it within accountability theory. The general pros of systematic literature reviews apply as well: it is replicable and transparent about the procedure, which I, as I work on the topic of accountability, particularly appreciate.
However, there are also a big drawback to this approach. It is a quite cumbersome process. It takes a lot of time, perhaps even more so than a regular systematic literature review. It requires not only the normal amount of reading, but the process starts way earlier: with systematically designing a query for the review to base oneself on which requires screening a large amount of titles/abstracts. Nevertheless, I would argue that the disadvantage does not outweigh the advantages, as it would do well for any systematic literature review to be transparent about that one crucial thing which will define the entire review: its query.
Finally, some words about reliability and validity. In order to see if my approach was valid, I cross checked the final selection with the initial 27 articles. 20 of the 27 articles were found in either database. Of the 7 articles which were not found, 4 were not indexed by SCOPUS/WoS at the time of scraping, but were added later and do show up in a later query. In the final 3 cases, the articles were indexed in SCOPUS/WoS, but did not show up because they could not be found through the query. As such, 24 out of 27 initial articles would have been found by the query, and all of the material is present in one or both of the databases. Thus, choosing Web of Science and SCOPUS was sensible, and the query did do relatively well. Nevertheless, it is not a perfect method (3 articles were not found). One possible explanation for this is the use of keywords, which are author-generated, in some cases these may not be well chosen. In other cases they just do not show up as part of the most commonly used keywords around the topic. That is unfortunate, but an expected side-effect.
We have also seen that between 96-98% of the articles returned by the query have been excluded after manual assessment. The method thus can be said not to be very reliable in the traditional sense (cf. fig. 5). However, this, again, is to be expected due to the ‘fuzzy’ nature of the phenomenon: which will require a) a lot of balancing of the researcher’s part in the query design, and b) will always lead to a lot of white noise in the query results.
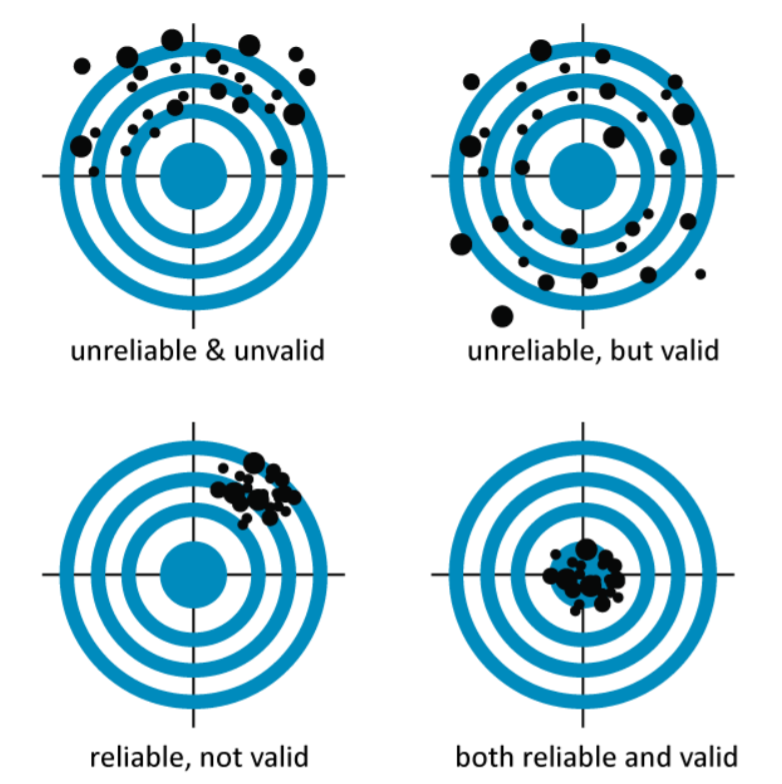
Fig. 5. Diagram showing the difference between validity and reliability. (Barford, 2014; modified from Nevit Dilmen)
In conclusion, the methodology sketched above is in my experience a beneficial one, in that it is comprehensive and allows for an interdisciplinary and bottom-up perspective on assessing academic discourse around a ‘fuzzy’ phenomenon. While critics may rightly point to the lack of reliability precisely due to its fuzzy nature, I found the approach to be valid in that it provides a systematic account for the query construction, and allows for an open-minded approach to a topic.
Endnotes
[1] Settings were as follows:
Threads number: 3 | Tolerance (speed): 1.0 | Approximate Repulsion: off | Approximation: 1.2 | Scaling: 50.0 | Stronger Gravity: off | Gravity: 0.5 | Dissuade hubs: off | LinLog mode: off | Prevent overlap: off | Edge Weight Influence: 1.0. Ended at iteration 125,551.
[2] While the order (term 1 à term 2 / term 2 à term 1) is important for collocation, it is not relevant for query design.
[3] The cutoff point was chosen as the edge weights 12 up to and including 5, represented two-third of the edge weight scale.
[4] As the query consisted of many abstract terms (e.g. transparency) a lot of bycatch occurred. Determining the relevance of a publication was sometimes straightforward, for instance in cases where a system was introduced, rather than the reflection on a system (e.g. Lee, Aydin, Choi, Lekhavat, & Irani, 2018). In other cases relevance was easily assessed (e.g. McGrath & Gupta, 2018). There were also ambiguous cases (e.g. Rizk, Awad, & Tunstel, 2018) in which the title and abstract were insufficient to determine whether the main topic of the publication was about algorithmic accountability.
References
Ananny, M. (2016). Toward an Ethics of Algorithms: Convening, Observation, Probability, and Timeliness. Science Technology and Human Values, 41(1), 93–117. https://doi.org/10.1177/0162243915606523
Ananny, M., & Crawford, K. (2018). Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media and Society, 20(3), 973–989. https://doi.org/10.1177/1461444816676645
Barad, K. (2007). Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning. Durham/London: Duke University Press.
Barfod, K. W. (2014). Achilles tendon rupture; Assessment of non- operative treatment Achilles tendon Total Rupture Score Standard Error of the Measurement. Danish Medical Journal, 61(4).
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: an open source software for exploring and manipulating networks. In Proceedings of the Third International ICWSM Conference. Retrieved from http://www.aaai.org/ocs/index.php/ICWSM/09/paper/download/154/1009
Beall’s List. (2018). Beall’s list of Predatory Journals and Publishers. Retrieved July 4, 2018, from https://beallslist.weebly.com/
Bennett Moses, L., & Chan, J. (2018). Algorithmic prediction in policing: assumptions, evaluation, and accountability. Policing and Society, 28(7), 806–822. https://doi.org/10.1080/10439463.2016.1253695
Binns, R. (2017). Algorithmic Accountability and Public Reason. Philosophy & Technology. https://doi.org/10.1007/s13347-017-0263-5
Binns, R., Van Kleek, M., Veale, M., Lyngs, U., Zhao, J., & Shadbolt, N. (2018). “It’s Reducing a Human Being to a Percentage”; Perceptions of Justice in Algorithmic Decisions. In CHI ’18. https://doi.org/10.1145/3173574.3173951
Blondel, V. D., Guillaume, J.-L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10), 1–12. https://doi.org/10.1088/1742-5468/2008/10/P10008
Bovens, M. (2007). Analysing and Assessing Accountability: A Conceptual Framework. European Law Journal, 13(4), 447–468. https://doi.org/10.1111/j.1468-0386.2007.00378.x
Bozdag, E. (2013). Bias in algorithmic filtering and personalization. Ethics and Information Technology, 15(3), 209–227. https://doi.org/10.1007/s10676-013-9321-6
Burrell, J. (2015). How the Machine “Thinks:” Understanding Opacity in Machine Learning Algorithms. Ssrn, (June), 1–12. https://doi.org/10.2139/ssrn.2660674
de Laat, P. B. (2017). Algorithmic Decision-Making Based on Machine Learning from Big Data: Can Transparency Restore Accountability? Philosophy & Technology. https://doi.org/10.1007/s13347-017-0293-z
Denscombe, M. (2017). The good research guide: for small-scale social science research projects (6th ed.). London: McGraw-Hill Education.
Diakopoulos, N. (2015). Algorithmic Accountability: Journalistic investigation of computational power structures. Digital Journalism, 3(3), 398–415. https://doi.org/10.1080/21670811.2014.976411
Drew, C. (2016). Data science ethics in government. Philosophical Transactions of the Royal Society, 374(2083), 20160119. https://doi.org/10.1098/rsta.2016.0119
Edwards, L., & Veale, M. (2017). Enslaving the algorithm : from a ‘right to an explanation’ to a ‘right to better decisions’?
Fink, K. (2018). Opening the government’s black boxes: freedom of information and algorithmic accountability. Information Communication and Society, 21(10), 1453–1471. https://doi.org/10.1080/1369118X.2017.1330418
Geerts, E., & Van der Tuin, I. (2016). Diffraction & reading diffractively. Retrieved April 23, 2019, from http://newmaterialism.eu/almanac/d/diffraction.html
Gieseking, J. J. (2018). Operating anew: Queering GIS with good enough software. Canadian Geographer, 62(1), 55–66. https://doi.org/10.1111/cag.12397
Jacomy, M., Venturini, T., Heymann, S., & Bastian, M. (2014). ForceAtlas2, a continuous graph layout algorithm for handy network visualization designed for the Gephi software. PLoS ONE, 9(6), 1–12. https://doi.org/10.1371/journal.pone.0098679
Kemper, J., & Kolkman, D. (2018). Transparent to whom? No algorithmic accountability without a critical audience. Information Communication and Society, 1–16. https://doi.org/10.1080/1369118X.2018.1477967
Kraemer, F., Overveld, K. Van, & Peterson, M. (2011). Is there an ethics of algorithms ? Ethics and Information Technology, 13(3), 251–260. https://doi.org/10.1007/s10676-010-9233-7
Lee, H., Aydin, N., Choi, Y., Lekhavat, S., & Irani, Z. (2018). A decision support system for vessel speed decision in maritime logistics using weather archive big data. Computers & Operations Research, 98, 330–342.
Lepri, B., Oliver, N., Letouzé, E., Pentland, A., & Vinck, P. (2017). Fair, Transparent, and Accountable Algorithmic Decision-making Processes. Philosophy & Technology. https://doi.org/10.1007/s13347-017-0279-x
Liberati, A., Altman, D. G., Tetzlaff, J., Mulrow, C., Gøtzsche, P. C., Ioannidis, J. P. A., … Moher, D. (2009). The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. PLoS Medicine, 6(7). https://doi.org/10.1371/journal.pmed.1000100
Lustig, C., Pine, K., Nardi, B., Irani, L., Lee, M. K., Nafus, D., & Sandvig, C. (2016). Algorithmic Authority: The Ethics, Politics, and Economics of Algorithms that Interpret, Decide, and Manage. Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems – CHI EA ’16, 1057–1062. https://doi.org/10.1145/2851581.2886426
McGrath, J., & Gupta, A. (2018). Writing a Moral Code: Algorithms for Ethical Reasoning by Humans and Machines. Religions, 9(8), 240–259.
Mittelstadt, B. D., Allo, P., Taddeo, M., Wachter, S., & Floridi, L. (2016). The ethics of algorithms: Mapping the debate. Big Data & Society, 3(2), 205395171667967. https://doi.org/10.1177/2053951716679679
Neyland, D. (2016). Bearing Account-able Witness to the Ethical Algorithmic System. Science, Technology, & Human Values, 41(1), 50–76. https://doi.org/10.1177/0162243915598056
Neyland, D., & Möllers, N. (2017). Algorithmic IF … THEN rules and the conditions and consequences of power. Information Communication and Society, 20(1), 45–62. https://doi.org/10.1080/1369118X.2016.1156141
Plain, C. (2007). Build an Affinity for K-J Method. Quality Progress, 40(3), 88.
Rahwan, I. (2018). Society-in-the-loop: programming the algorithmic social contract. Ethics and Information Technology, 20(1), 5–14. https://doi.org/10.1007/s10676-017-9430-8
Rizk, Y., Awad, M., & Tunstel, E. W. (2018). Decision Making in Multi-Agent Systems: A Survey. In IEEE Transactions on Cognitive and Developmental Systems.
Saurwein, F., Just, N., & Latzer, M. (2015). Governance of algorithms: Options and limitations. Info, 17(6), 35–49. https://doi.org/10.1108/info-05-2015-0025
Vedder, A., & Naudts, L. (2017). Accountability for the use of algorithms in a big data environment. International Review of Law, Computers and Technology, 31(2), 206–224. https://doi.org/10.1080/13600869.2017.1298547
Williamson, B. (2015). Governing software: networks, databases and algorithmic power in the digital governance of public education. Learning, Media and Technology, 40(1), 83–105. https://doi.org/10.1080/17439884.2014.924527
Yeung, K. (2017a). Algorithmic regulation: A critical interrogation. Regulation & Governance, (April), 1–19. https://doi.org/10.1111/rego.12158
Yeung, K. (2017b). “Hypernudge”: Big Data as a mode of regulation by design. Information, Communication and Society, 20(1), 118–136. https://doi.org/10.1080/1369118X.2016.1186713
Zarsky, T. (2016). The Trouble with Algorithmic Decisions : An Analytic Road Map to Examine Efficiency and Fairness in Automated and Opaque Decision Making. Science Technology and Human Values, 41(1), 118–132. https://doi.org/10.1177/0162243915605575
Ziewitz, M. (2016). Governing Algorithms: Myth, Mess, and Methods. Science Technology and Human Values, 41(1), 3–16. https://doi.org/10.1177/0162243915608948