
Onderzoek naar de Nederlandse Twittersfeer
Door: Maranke Wieringa, Ludo Gorzeman, Daniela van Geenen, Mirko Tobias Schäfer
In een team van onderzoekers verbonden aan de Data School (Universiteit Utrecht) en de Hogeschool Utrecht, voornamelijk het lectoraat Crossmediale Kwaliteitsjournalistiek zijn we in een langlopend project bezig om de Nerderlangs(talig)e Twittersfeer in kaart te brengen. Het onderzoek in opdracht van Vrij Nederland en Nieuwsuur is een van de spin-offs die uit een deelonderzoek naar interessegroepen – op professioneel en privé vlak -, de diversiteit aan (cross-)mediapraktijken, en wat wij noemen, ‘sociaal filteren’ en ‘framen’ van content op het platform, dus de manieren waarop users mediumcontent selecteren, modereren en (verder)verspreiden. Dit deelonderzoek werd uitgevoerd door Maranke Wieringa, Ludo Gorzeman en Daniela van Geenen, onder leiding van Mirko Tobias Schäfer. Op grond van een dataset met alle Nederlandstalige tweets uit de periode 4-18 september 2016, verzameld door Buzzcapture identificeerden wij ca. 1200 retweetclusters rond topics (voor een gedetailleerde beschrijving van de methode zie hieronder Methodologie). Baserend hierop brachten we in kaart welke clusters er te onderscheiden zijn onder politiek geïnteresseerde Twitteraars.
Vervolgens werd onderzocht aan welke media er binnen de rechtse en ‘centrum-linkse’ clusters werd gerefereerd, en werd op basis van een steekproef van drie keer 500 tweets geanalyseerd hoe negatief, positief of neutraal binnen beide clusters en het gehele netwerk op mediaberichten werd gereageerd.
Daarnaast onderzochten de studenten Luana Gomes Sousa e Sousa, Marjolein Krijgsman en Robin Lambriex de samenhang tussen activiteiten op sociale media en berichtgeving in de mainstream media op basis van een sample van tweets over de Sleepwet in de periode 30 september-23 november 2017 (voor een uitgebreide beschrijving van dit deelonderzoek, download hier het onderzoek).
De lijsten van rechtse en ‘linkse’ Twitteraars zijn gebaseerd op een eigen verkenning van Vrij Nederland en Nieuwsuur.
De meest relevante resultaten op een rij
- We kunnen door middel van netwerkanalyse (voor uitleg zie “Gemeenschapsherkenning op Twitter” onderin) een groot aantal verschillende Twitter ‘topic communities’ in de dataset traceren. We keken in dit onderzoek naar twee clusters van politiek-geïnteresseerde Twitter-gebruikers, een groep die ideologisch rechts staat en een groep die meer als centrum-links te classificeren is.


Afbeelding 1: Retweet-netwerk; het netwerk van Nederlandstalige retweets die verstuurd zijntussen 4 en 18 september 2016. Te zien zijn de meest actieve Nederlandstalige accounts (zeven procent, 42.721 van 608.634 accounts) die tenminste 10 keer geretweet werden of zelf retweets verstuurden. In het blauw zie je de gematigd linkse kluwen, die in z'n geheel bestaat uit zo'n veertigduizend twitteraars, en zicht uitstrekt over de verschillende twittersferen. De donkergroene bubbel bestaat uit rechtse twitteraars (zo'n vijftienduizend), en is zichtbaar kleiner en geconcentreerd.De visualisatie is gemaakt in Gephi (Bastian et al., 2009), waarin het ForceAtlas2 (Jacomy et al., 2014) algoritme is toegepast. Dit algoritme is een force-vector layout algoritme, dat een krachtenveld simuleert waarin edges (RTs) elkaar aantrekken en nodes (accounts) elkaar afstoten.
- De ‘rechtse’ groep is duidelijk homogeen – ze retweeten vooral elkaar; de centrum-linkse groep veel heterogener – users retweeten ook accounts die in andere clusters te vinden zijn.
- Gebruikers in beide clusters refereren vaak aan andere media (kranten, TV, radio en websites).

Afbeelding 2: De top van domeinen waarnaar gerefereerd werd in het totale RT-netwerk. - Mainstream media of traditionele media werken als ‘versterker’ voor social media-activiteiten. Het onderzoek naar #Sleepwet toont aan dat de uitzending “Zondag met Lubach” tot een flinke toename aan social media-activiteit heeft geleid. Er zijn meer dergelijke voorbeelden in internationaal onderzoek naar Twitter (vgl. Benkler et al., 2017; Zannettou et al., 2017).

Afbeelding 3: Online nieuws en tweets over de Sleepwet. - In onze dataset van twee weken Twitter NL kunnen we ook zien dat thema’s geen gehoor vinden. Het was de periode waarin in het politieke landschap de donor-wet en de wet die zorgverzekeraars inzage biedt in patiëntendossiers bediscussieerd werden. Dit laatste werd binnen onze dataset nauwelijks besproken en kreeg ook in de media niet veel aandacht. Ten opzichte van privacy en data-ethiek achten we het wel een veel problematischere wet dan de donorwet die ruim de aandacht in de media en op Twitter kreeg.
- De dynamiek tussen social media en traditionele media wordt niet alleen bepaald door de manier waarop traditionele media aan sociale media refereren, maar ook hoe de gebruikers uit het aanbod van de traditionele media kiezen. Deze keuze onderstreept dikwijls wat het beste past bij hun eigen interesses, hun ideologische houding en de achterban waarmee de artikelen gedeeld worden.
- Gebruikers voegen vaak juist een positief of negatief getint commentaar toe aan de mediaberichten. Uit een kleine – niet-representatieve steekproef – blijkt dat deze commentaren in het ‘rechtse’ cluster vaker negatief zijn.
- Lijst van 50 meest gelinkte domains en hun eigenaren binnen de twee bestudeerde clusters over de periode 2-18 september 2016:
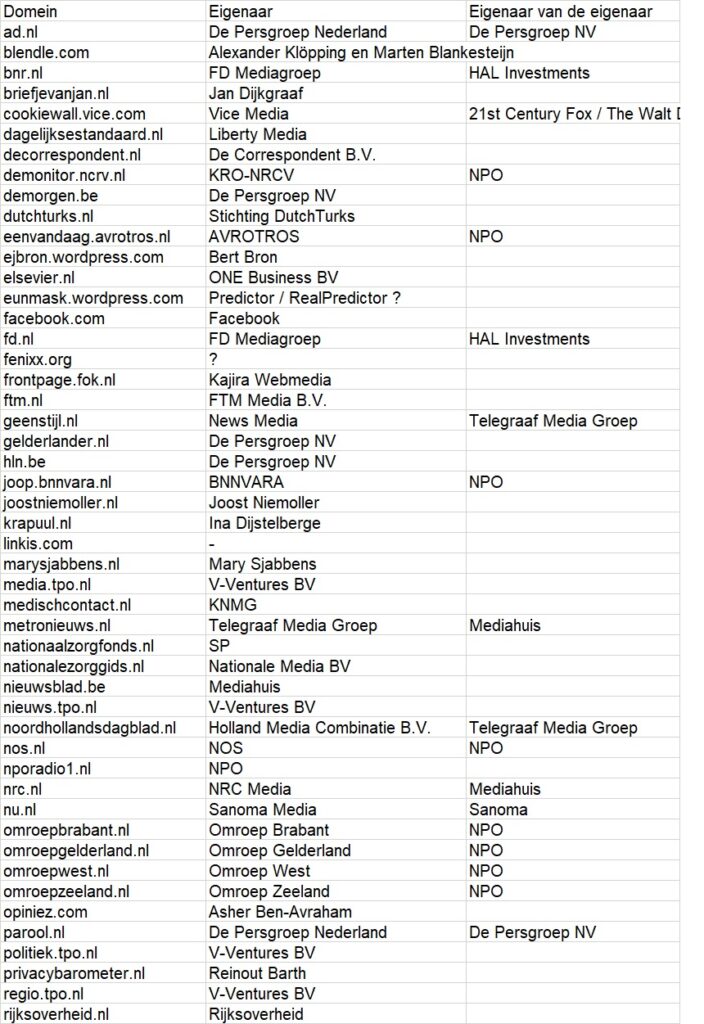
Tabel 1: Alfabetisch overzicht van de 50 meest aangehaalde URL’s in de bestudeerde twee clusters. - Top vier domeinen cluster ‘rechts’:
- Telegraaf.nl
- TPO.nl
- Geenstijl.nl
- Volkskrant.nl
- Top vier domeinen cluster ‘centrum-links’:
- Nos.nl
- Volkskrant.nl
- Youtube.com
- Telegraaf.nl
- Methodologie clusteranalyse: Gemeenschapsherkenning op Twitter (Ludo Gorzeman)
De Nederlandstalige Twitter-gemeenschap is geen homogeen geheel: veel Twitteraars krijgen elkaar nooit te zien of te spreken, maar acteren voornamelijk binnen een eigen sub-gemeenschap, veelal gevormd rondom gedeelde interesses, op professioneel of privé vlak. Deze sub-gemeenschappen, ofwel clusters, zijn door middel van data-analyse redelijkerwijs geautomatiseerd te herkennen. De basis voor de gemeenschapsherkenning die in dit onderzoek is toegepast ligt in retweet-gedrag. Sterker nog dan bij followers, friends of @replies kan een retweet gezien worden als een affirmatie van het bericht van de ander. De retweet is daarmee een duidelijk kwantificeerbare indicatie voor een positieve onderlinge band tussen twee Twitteraars. Stellen we nu dat een gemeenschap gevormd is door positieve onderlinge banden, dan kunnen we die gemeenschappen op Twitter herkennen door te kijken welke groepen de meeste onderlinge retweets hebben.Om dit te bereiken zetten we eerst de dataset met alle Nederlandstalige tweets om naar een graaf, dat wil zeggen een verzameling punten met onderlinge lijnen. Iedere Twitteraar die in de dataset voorkomt wordt gerepresenteerd door een punt (ook wel een node genoemd) in de graaf. Voor iedere retweet in de dataset wordt een lijn (ook wel een edge genoemd) geplaatst tussen de punten die staan voor enerzijds de Twitteraars die retweeten en anderzijds de Twitteraars die geretweet worden. Een fictief voorbeeld van een kleine dataset kan er dan als volgt uit zien: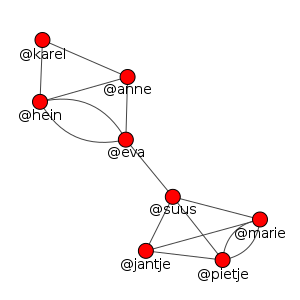 Hier zien we 8 Twitteraars die qua retweet-gedrag duidelijk op te delen zijn in een tweetal clusters: enerzijds karel, hein, anne en eva, en anderzijds suus, jantje, marie en pietje. De veronderstelling is dat omdat deze twee groepen elkaar onderling meer retweeten dan dat er tussen het gehele netwerk wordt geretweet – de twee groepen staan immers alleen via eva en suus met elkaar in verbinding – zij een sterkere positieve onderlinge band hebben en dus als twee aparte gemeenschappen gezien kunnen worden.Binnen daadwerkelijke grotere datasets zoals de twee weken Nederlandstalig Twitter die wij bestudeerd hebben, zijn de sub-gemeenschappen helaas niet meer zo duidelijk direct herkenbaar. Toch kunnen we de computer laten rekenen op zoek naar groepen van Twitteraars die meer onderlinge retweets hebben dan dat ze retweets naar de rest van het netwerk hebben. Hiervoor gebruiken wij het algoritme van Blondel et al. (2008) dat zo efficiënt mogelijk poogt deze groepen te herkennen.Twee dingen vallen daarbij direct op: ten eerste zijn er een flink aantal Twitteraars die gedurende de twee weken die wij bestudeerd hebben niet geretweet hebben, noch geretweet zijn. Deze Twitteraars vallen weg uit onze analyse. Ten tweede zijn er een boel minuscule groepen die geen enkele aansluiting hebben bij het grote netwerk, dit zijn groepjes van twee of drie Twitteraars die elkaar geretweet hebben, maar verder helemaal geen retweets van of naar de rest van het netwerk hebben. Ook deze Twitteraars hebben wij verder buiten beschouwing gelaten.Wat overblijft is een groot netwerk waarin door het algoritme ruim 400 sub-gemeenschappen zijn herkend. Deze sub-gemeenschappen verschillen in hechtheid en soms zijn de grenzen tussen de verschillende sub-gemeenschappen maar vagelijk te herkennen. In onderstaand figuur, een wat grotere fictieve dataset waarbij de punten gekleurd zijn naar lidmaatschap van herkende gemeenschappen, is bijvoorbeeld het blauwe cluster vrij duidelijk te onderscheiden, terwijl de grens tussen het groene en oranje cluster redelijk vaag is.
Hier zien we 8 Twitteraars die qua retweet-gedrag duidelijk op te delen zijn in een tweetal clusters: enerzijds karel, hein, anne en eva, en anderzijds suus, jantje, marie en pietje. De veronderstelling is dat omdat deze twee groepen elkaar onderling meer retweeten dan dat er tussen het gehele netwerk wordt geretweet – de twee groepen staan immers alleen via eva en suus met elkaar in verbinding – zij een sterkere positieve onderlinge band hebben en dus als twee aparte gemeenschappen gezien kunnen worden.Binnen daadwerkelijke grotere datasets zoals de twee weken Nederlandstalig Twitter die wij bestudeerd hebben, zijn de sub-gemeenschappen helaas niet meer zo duidelijk direct herkenbaar. Toch kunnen we de computer laten rekenen op zoek naar groepen van Twitteraars die meer onderlinge retweets hebben dan dat ze retweets naar de rest van het netwerk hebben. Hiervoor gebruiken wij het algoritme van Blondel et al. (2008) dat zo efficiënt mogelijk poogt deze groepen te herkennen.Twee dingen vallen daarbij direct op: ten eerste zijn er een flink aantal Twitteraars die gedurende de twee weken die wij bestudeerd hebben niet geretweet hebben, noch geretweet zijn. Deze Twitteraars vallen weg uit onze analyse. Ten tweede zijn er een boel minuscule groepen die geen enkele aansluiting hebben bij het grote netwerk, dit zijn groepjes van twee of drie Twitteraars die elkaar geretweet hebben, maar verder helemaal geen retweets van of naar de rest van het netwerk hebben. Ook deze Twitteraars hebben wij verder buiten beschouwing gelaten.Wat overblijft is een groot netwerk waarin door het algoritme ruim 400 sub-gemeenschappen zijn herkend. Deze sub-gemeenschappen verschillen in hechtheid en soms zijn de grenzen tussen de verschillende sub-gemeenschappen maar vagelijk te herkennen. In onderstaand figuur, een wat grotere fictieve dataset waarbij de punten gekleurd zijn naar lidmaatschap van herkende gemeenschappen, is bijvoorbeeld het blauwe cluster vrij duidelijk te onderscheiden, terwijl de grens tussen het groene en oranje cluster redelijk vaag is.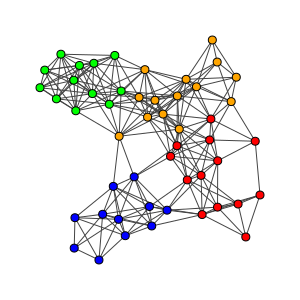 Om hiervoor te compenseren hebben we voor iedere Twitteraar de zogenaamde Pagerank binnen het cluster berekend (Page et al., 1998). De Pagerank geeft een numerieke indicatie van hoe centraal en dicht verweven een bepaald punt binnen een graaf staat. Van iedere Twitteraar hebben we dus berekend hoe centraal deze binnen de herkende gemeenschap staat. Alle berekeningen aan data uit de gemeenschappen en alle samples die we uit de gemeenschappen hebben gehaald zijn gewogen naar gelang de Pagerank. De Twitteraars die centraal in een herkende gemeenschap staan tellen bij onze berekeningen dus sterker mee dan degene die zich in een vaag grensgebied bevinden.
Om hiervoor te compenseren hebben we voor iedere Twitteraar de zogenaamde Pagerank binnen het cluster berekend (Page et al., 1998). De Pagerank geeft een numerieke indicatie van hoe centraal en dicht verweven een bepaald punt binnen een graaf staat. Van iedere Twitteraar hebben we dus berekend hoe centraal deze binnen de herkende gemeenschap staat. Alle berekeningen aan data uit de gemeenschappen en alle samples die we uit de gemeenschappen hebben gehaald zijn gewogen naar gelang de Pagerank. De Twitteraars die centraal in een herkende gemeenschap staan tellen bij onze berekeningen dus sterker mee dan degene die zich in een vaag grensgebied bevinden.
Referenties
Bastian, M., Heymann, S. and Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Proceedings Third International ICWSM Conference. https://gephi.org/publications/gephi-bastian-feb09.pdf.
Benkler, Y., Faris, R., Roberts, H. & Zuckerman, E. (March 3, 2017). “Study: Breitbart-led right-wing media ecosystem altered broader media agenda.” Columbia Journalism Review 1.4.1 (2017): 7. https://www.cjr.org/analysis/breitbart-media-trump-harvard-study.php
Blondel, V. D., Guillaume, J.-L., Lambiotte, R. and Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment 2008(10), pp. 1–12. http://doi.org/10.1088/1742-5468/2008/10/P10008.
Jacomy, M., Heymann, S., Venturini, T. and Bastian, M. (2014). ForceAtlas2. A Continuous Graph Layout Algorithm for Handy Network Visualization. PLoS ONE 9(6). http://dx.doi.org/10.1371/journal.pone.0098679.
Page, L., Brin, S., Motwani, R. & Winograd, T. (1998). The PageRank Citation Ranking: Bringing Order to the Web. World Wide Web Internet And Web Information Systems 54, no. 1999–66, pp. 1–17. doi:10.1.1.31.1768.
Zannettou, S., Caulfield, T., De Cristofaro, E., Kourtellis, N., Leontiadis, I., Sirivianos, M., Stringhini, G. & Blackburn, J. (2017). The Web Centipede: Understanding How Web Communities Influence Each Other Through the Lens of Mainstream and Alternative News Sources. arXiv preprint arXiv:1705.06947. https://phys.org/news/2017-11-fringe-reddit-4chan-high-alternative.html.